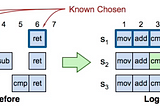
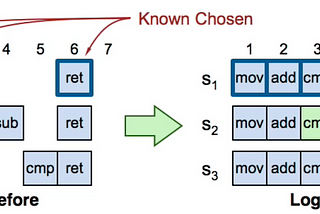
Ziliang LininDistributed KnowledgePaxos consensus for beginners (2)This is the second article about the introduction of Paxos — a consensus algorithm for distributed system replication; it’s highly…5 min read·Nov 3, 2020--2--2
Ziliang LininDistributed KnowledgePaxos consensus for beginnersSince its first publication The part-time parliament by Leslie Lamport in 1989, Paxos has been the core of distributed consensus…8 min read·May 14, 2020--2--2